4 min to complete
A Cluster is a collection of nodes that ScyllaDB uses to store the data. The nodes are logically distributed like a ring. A minimum cluster typically consists of at least three nodes. Data is automatically replicated across the cluster, depending on the Replication Factor.
This cluster is often referred to as a ring architecture, based on a hash ring — the way the cluster knows how to distribute data across the different nodes.
A cluster can change size over time, adding more nodes (to expand storage and processing power) or removing nodes (either through purposeful decommissioning or system failure). When a topology change occurs, the ScyllaDB cluster is designed to reconfigure itself and rebalance the data held within it automatically.
A ScyllaDB cluster can contain a minimum of three nodes, but it can also have hundreds of nodes in it.
Within the ScyllaDB cluster, all internode communication is peer-to-peer, so there is no single point of failure. For communication outside of the cluster, such as a read or write, a ScyllaDB client will communicate with a single server node, called the coordinator. The selection of the coordinator is made with each client connection request to prevent bottlenecking requests through a single node. This is further explained later on in this lesson.
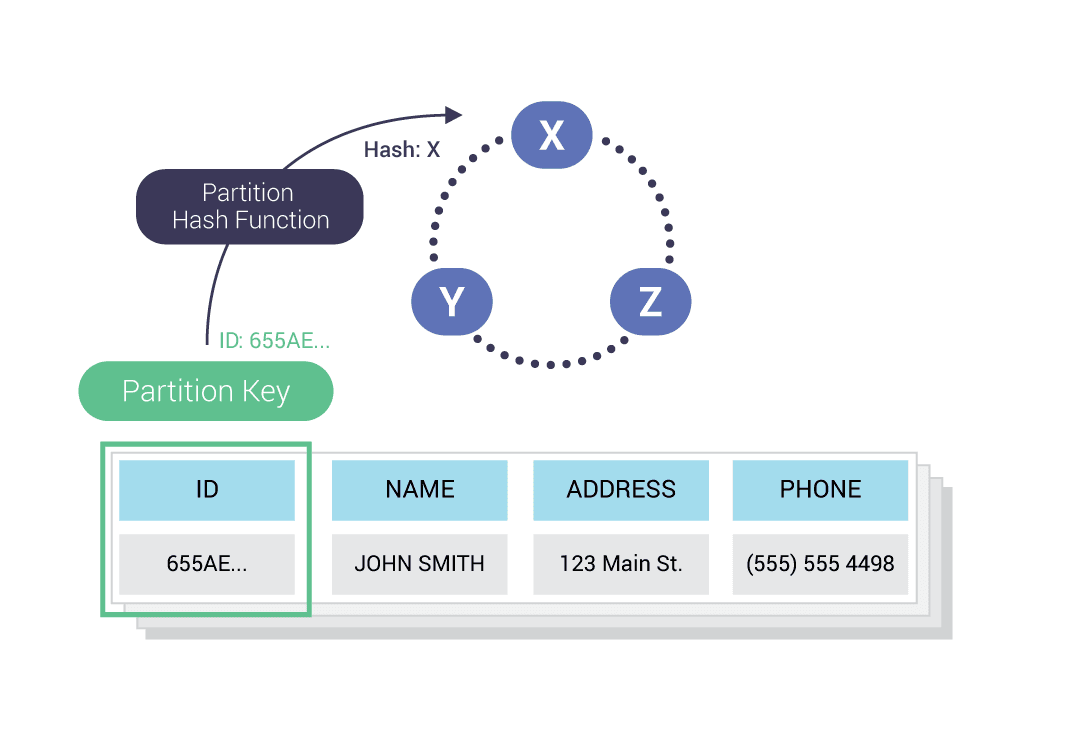
A Partition Key is one or more columns that are responsible for data distribution across the nodes. It determines in which nodes to store a given row. As we will see later on, typically, data is replicated, and copies are stored on multiple nodes. This means that even if one node goes down, the data will still be available. It ensures reliability and fault tolerance
In the example below, the Partition Key is the ID column. A consistent hash function is used to determine to which nodes data is written.
ScyllaDB transparently partitions data and distributes it to the cluster. Data is replicated across the cluster. A ScyllaDB cluster is visualized as a ring, where each node is responsible for a range of tokens, and each value is attached to a token using a partition key:
Learn more about partition keys in the Data Model lesson.
