This is the first Data Modeling lesson in a two-part series. Data modeling is the process of identifying the entities in our domain, the relationships between these entities and how they will be stored in the database.
Note: The lesson includes a hands-on example that you can run on a local machine with Docker. Alternatively, you can find this lab embedded here. Using the embedded lab environment provides an interactive virtual machine where you can execute all the commands directly from your browser without the need to configure anything.
The main steps of data modeling in ScyllaDB are:
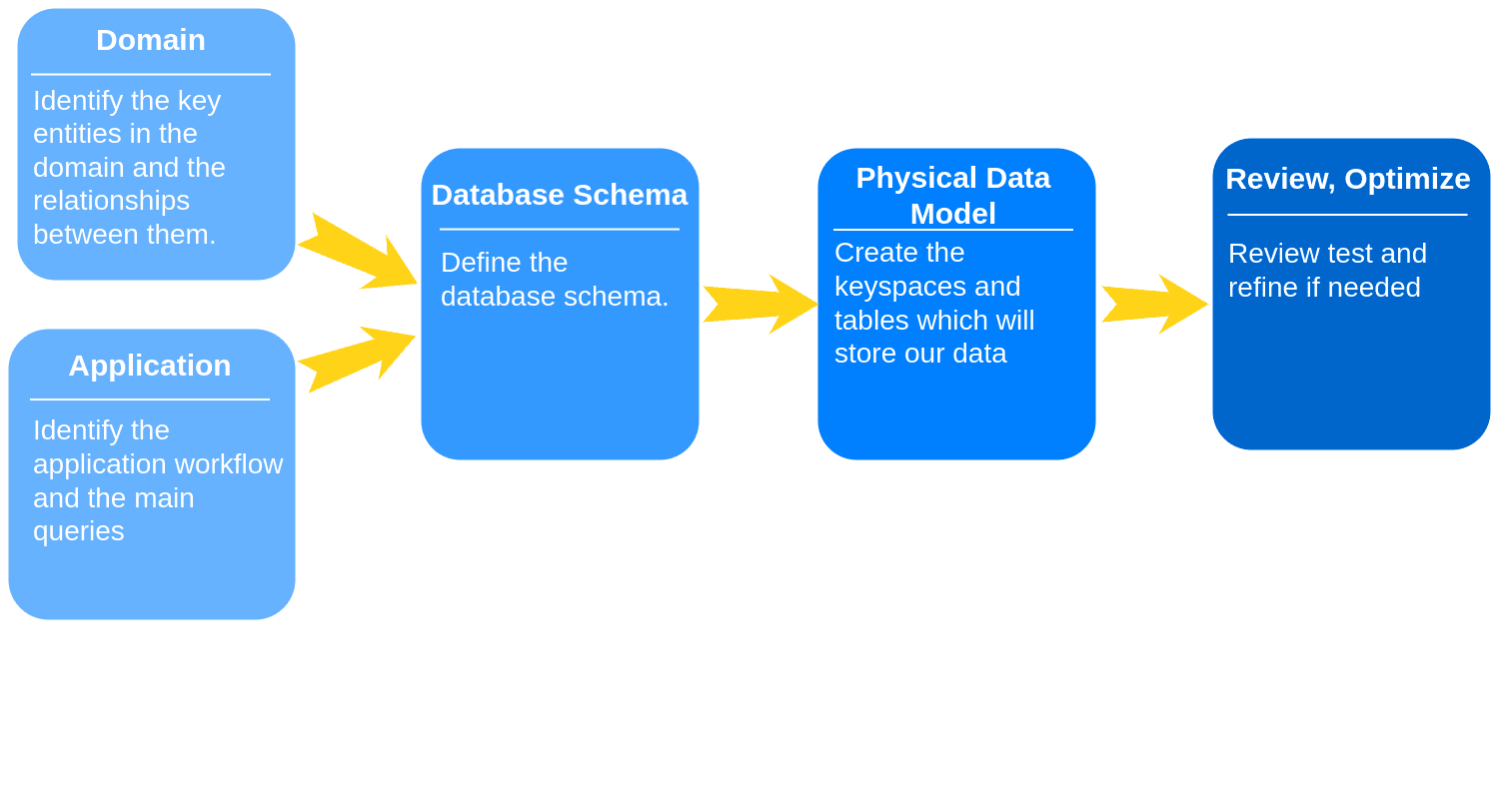
The focus of this lesson is the parts of data modeling that are unique to ScyllaDB (and Apache Cassandra) and not general data modeling. It is assumed that you have some prior data modeling experience.
After this lesson you will be able to:
- Describe the ScyllaDB data model
- Understand what a Keyspace, Table, Column, and Row are
- Explain the differences between a Primary Key, Partition Key, Compound Key, and Clustering Key
- Run a cqlsh and perform basic queries