2 min to complete

To summarize, these are the main points we covered:
- ScyllaDB data modeling is query-based. That is, we think of the application workflow and the queries early on in the data model process
- A Keyspace is a top-level container that stores tables
- A Table is how ScyllaDB stores data and can be thought of as a set of rows and columns
- The Primary Key is composed of the Partition Key and Clustering Key
- One of our goals in data modeling is even data distribution. For that, we need to select a partition key correctly
- Selecting the Primary Key is very important and has a huge impact on query performance
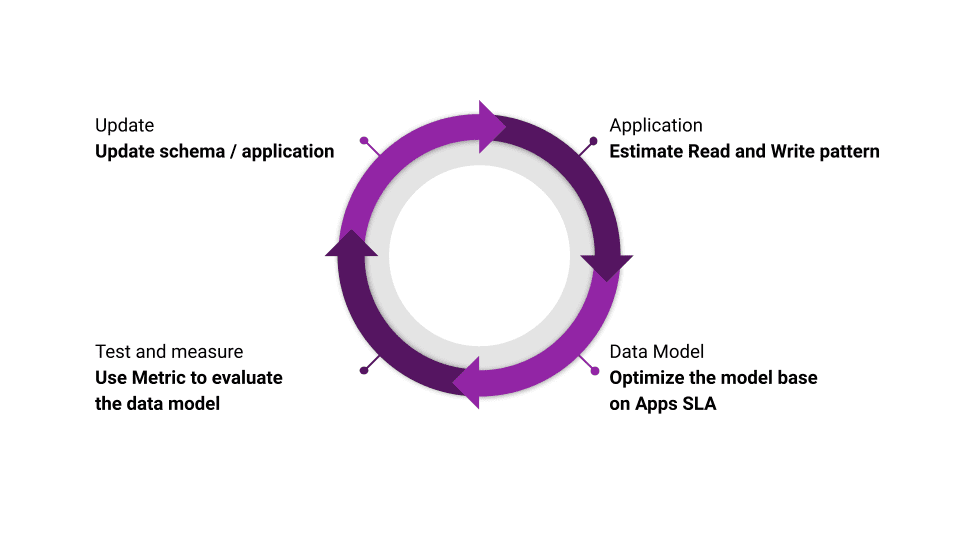
The data modeling process is iterative. It’s an ongoing process: