8 min to complete
In the previous lesson, we learned about partition and clustering keys and that each one of them can be composed of multiple columns. Now that we understand the concepts, how do we choose a suitable partition key?
To recap, in the previous lesson and this one, we use an example based around a Veterinary Clinic, named 4Paws Clinic. In this clinic, each animal which is admitted has a connected heart rate monitor, which logs heart rate and other vital information every five seconds.
What would make a good partition and clustering key?
To know that we would first have to think about our queries. Say our main query is to ask what’s the heart_rate of a given pet on a given day:
SELECT * from heartrate WHERE pet_chip_id = 123e4567-e89b-12d3-a456-426655440b23 AND date = '2019-09-05'A reminder, the Partition Key is responsible for data distribution across the nodes. It determines which node will store a given row. It can be one or more columns.
Setting up a One Node Cluster
Notice: if you took the previous lessons in this course, you already have a node called scyllaU up. If so, you can skip the first command.
Before starting the cluster, make sure the aio-max-nr value is high enough (1048576 or more).
This parameter determines the maximum number of allowable Asynchronous non-blocking I/O (AIO) concurrent requests by the Linux Kernel, and it helps ScyllaDB perform in a heavy I/O workload environment.
Check the value:
cat /proc/sys/fs/aio-max-nrIf it needs to be changed:
echo "fs.aio-max-nr = 1048576" >> /etc/sysctl.confsysctl -p /etc/sysctl.confOtherwise, start a single instance and call it ScyllaDBU:
docker run --name scyllaU -d scylladb/scylla:5.2.0Notice that some files might be downloaded in this step. After waiting for a few seconds, we’ll verify that the cluster is up and running with the Nodetool Status command:
docker exec -it scyllaU nodetool statusThe node scyllaU has a UN status. U means up, and N means normal. Read more about Nodetool Status Here.
Finally, we use the CQL Shell to interact with ScyllaDB:
docker exec -it scyllaU cqlshThe CQL Shell allows us to run Cassandra Query Language commands on ScyllaDB. Now create the Keyspace:
CREATE KEYSPACE Pets_Clinic WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor' : 1};Now identify the context for the next operations as the created Keyspace:
use Pets_Clinic; Option A
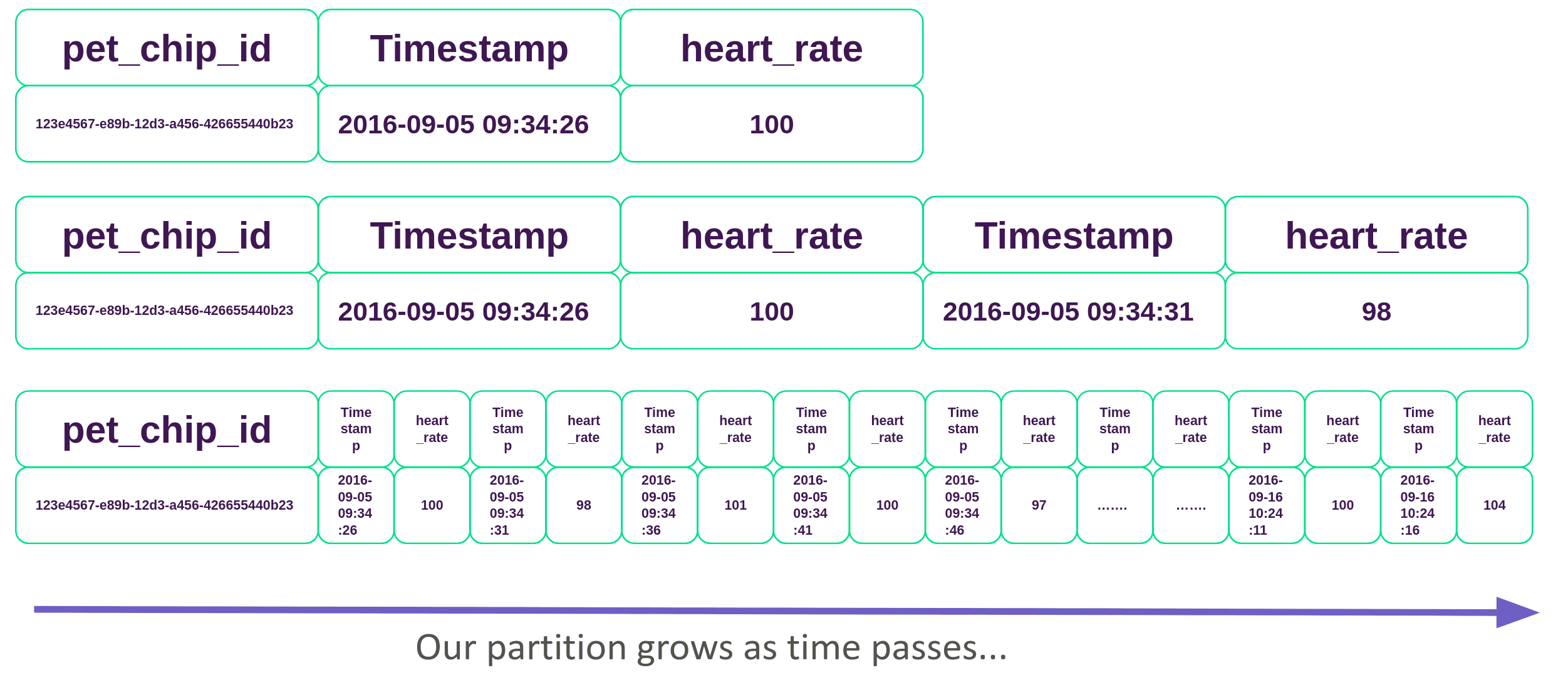
One option would be to use the pet_chip_id as the partition key.
CREATE TABLE heartrate_v1 (
pet_chip_id uuid,
date text,
time timestamp,
heart_rate int,
PRIMARY KEY (pet_chip_id, time));
While pet_chip_id is unique, each partition will have many rows, as for each pet, a heart rate is written every 5 seconds, and over time, each partition will grow and become a large partition.
Let’s insert some data:
INSERT INTO heartrate_v1(pet_chip_id, date, time, heart_rate) VALUES (123e4567-e89b-12d3-a456-426655440b23, '2019-09-05', '2019-09-05 09:34:26', 100);
INSERT INTO heartrate_v1(pet_chip_id, date, time, heart_rate) VALUES (123e4567-e89b-12d3-a456-426655440b23, '2019-09-05', '2019-09-05 09:34:31', 98);
INSERT INTO heartrate_v1(pet_chip_id, date, time, heart_rate) VALUES (123e4567-e89b-12d3-a456-426655440b23, '2019-09-05', '2019-09-05 09:34:36', 101);
Option B
A better option is to define a compound partition key with the pet_chip_id and day columns:
CREATE TABLE heartrate_v2 (
pet_chip_id uuid,
date text,
time timestamp,
heart_rate int,
PRIMARY KEY ((pet_chip_id,date), time));
In this case, we would be able to query by pet_chip, for a given day, without having large partitions. The partition size will be limited by the day. Every day, a new partition will be created for each pet.
When a large partition is written to disk, an entry in system.large_partitions will be created (or updated), read here about tracking large partitions.
Best Practices for selecting a partition and clustering key:
- Partitions are not too small.
- No large partitions
- Adequate per query (query according to partition key)
- The tradeoff of all expected queries
